可能我们平时有过以下疑问:
- C++函数和C函数有区别吗?
- C函数的调用过程是什么样的?
- C++函数的调用过程是什么样的?
- 类似 int sum(int, int)这样的函数,可以被正常调用并返回期望的结果吗?
- Obj* obj = nullptr; obj->show(); obj->get_name();可以编译通过吗?如果可以,运行后会显示什么?
- std::function、std::bind、lambda底层是怎么实现的?
1 |
|
后续示例代码编译环境:
- 操作系统:Windows7及以上(推荐Windows11)
- 编译器:Visual Studio 2010及以上(推荐Visual Studio 2022)
- 编译选项:x86 debug版本
- IDA反汇编工具
- 一个在线把C++翻译成汇编的网址:https://godbolt.org
没有Windows环境的,也可以借助这个网站来模拟学习,选择x86 msvc v19.lastest
本文涉及到的知识点包括:
- C++
- x86汇编
- 栈平衡
- 软件安全(缓冲区溢出攻击)
本文将从编译器的视角分析编译的C++程序。简单的通过利用调试器、调试器里的反汇编功能,来提供一种剖析C++的底层原理的思路,从而帮我们深入理解C++。
文中涉及到的示例代码均可在推荐的开发环境中编译和运行。
在分析开篇的那几个问题前,我们先看一个函数的调用过程
为此,我们采用一段简单的C++代码来说明:1
2
3
4
5
6
7
8
9
10
11
12
13
14// demo1.cpp
int sum(int a, int b) {
return a + b;
}
int main(int argc, char* argv[]) {
int num1 = sum(1, 2);
std::cout << num1 << std::endl;
return 0;
}
假设我们猜测int num = add(1, 2);调用过程如下:(当然也可以跳过假设直接查看反编译代码)1
2
3
4
5
6
7
8
9__asm {
pushad // 保存寄存器当前存储的值
push 2 // 把sum(1, 2); 中的参数2压栈
push 1 // 把sum(1, 2); 中的参数1压栈
call sum // 调用sum函数
add esp, 8 // 手动做栈平衡(如果把这行注释掉,栈就不平衡了,程序直接崩溃,可自行测试)
mov num1, eax // 把sum函数的执行结果,赋值给变量num1
popad // 恢复寄存器数值,恢复为pushad保存的数值
}
一些关于汇编的参考资料:
x86汇编指令集大全:https://zhuanlan.zhihu.com/p/53394807
机械指令 对应 汇编指令:https://blog.csdn.net/jzxin0/article/details/106069838
那么写一段完整代码来验证:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// demo1.cpp
int sum(int a, int b) {
return a + b;
}
int main(int argc, char* argv[]) {
int num1 = sum(1, 2);
std::cout << num1 << std::endl;
int num2 = 0;
// int num2 = sum(1, 2);函数调用过程,在编译器看来是等效于如下过程:
__asm {
pushad // 保存寄存器当前存储的值
push 2 // 把sum(1, 2); 中的参数2压栈
push 1 // 把sum(1, 2); 中的参数1压栈
call sum // 调用函数sum
add esp, 8 // 手动做栈平衡
mov num2, eax // 把sum的执行结果,赋值给变量num2
popad // 恢复寄存器原来的数值,恢复为pushad保存前的数值
}
std::cout << num2 << std::endl;
return 0;
}
上述代码运行结果如下: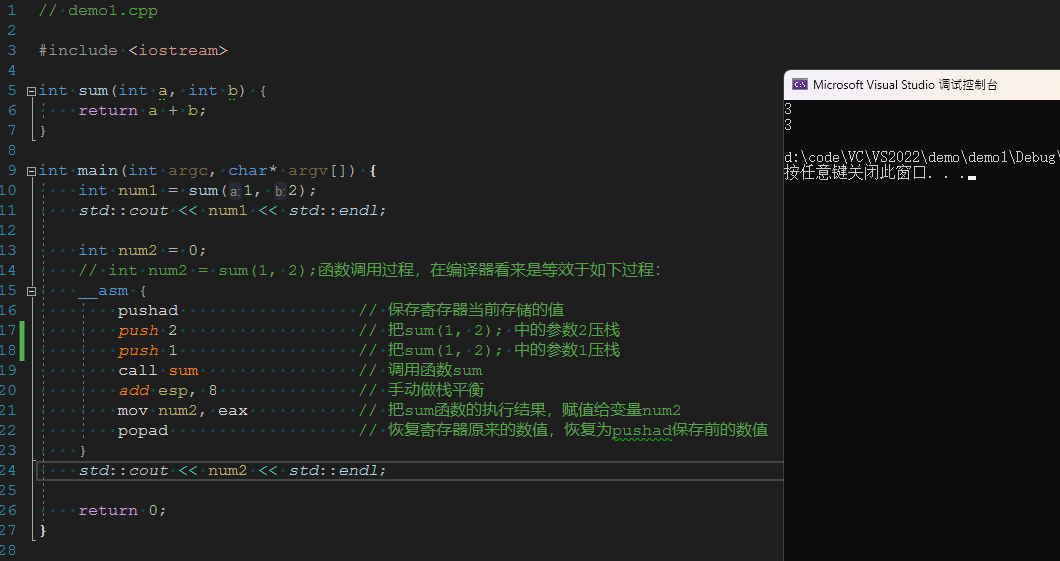
从执行结果来看,num1的值等于3,num2的值等于3,num1等于num2,也就是说这段内联汇编等效直接调用函数。由此我们可以猜测:
函数调用过程:在调用一个__cdecl调用约定的函数前,首先保护当前寄存器的数值,接着是参数入栈,然后调再用该函数,调用结束后接着做栈平衡,最后再恢复寄存的值为函数调用前的值。
那么我们如何验证我们猜测呢?
我们可以借助调试器的反汇编功能,在调用函数前设置一个断点,然后运行程序,等程序在断点处停下来后,点击鼠标右键选择转到反汇编
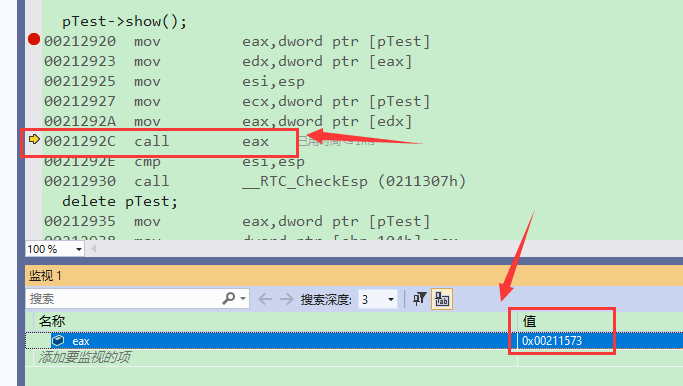
然后我们可以看到: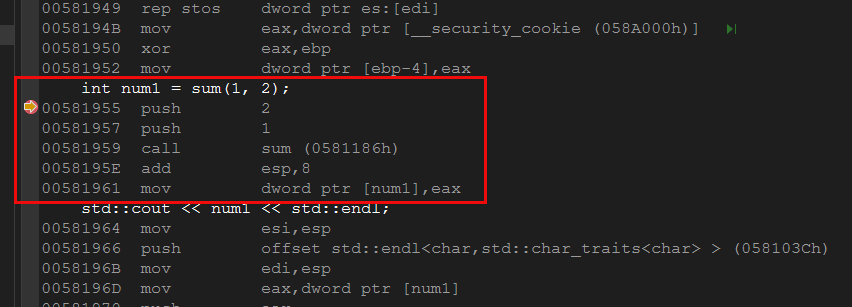
可以看到反汇编代码和我们编写的内联汇编代码思想一致,也就证明了我们上述结论是正确的。
这里我们在发散一下:
我知道CPU只能识别机器指令(0和1排列组合)。同时一个汇编指令对应一个机器指令,有没有一种可能让CPU直接执行我们写的0和1机器语言代码呢? 想起来还有点小激动。
为此我们需要补充一些汇编指令对应到机器码的知识,终于在学习若干小时候后(直接快进),我们得到如下代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62// demo2.cpp
int sum(int a, int b) {
return a + b;
}
int main(int argc, char* argv[]) {
int num1 = sum(1, 2);
std::cout << num1 << std::endl;
int num2 = 0;
// int num2 = sum(1, 2);函数调用过程,在编译器看来是等效于如下过程:
__asm {
pushad // 保存寄存器当前存储的值
push 2 // 把sum(1, 2); 中的参数2压栈
push 1 // 把sum(1, 2); 中的参数1压栈
call sum // 调用函数sum
add esp, 8 // 手动做栈平衡
mov num2, eax // 把sum的执行结果,赋值给变量num2
popad // 恢复寄存器原来的数值,恢复为pushad保存前的数值
}
std::cout << num2 << std::endl;
__asm {
push ebx
lea ebx, sum
}
// 下边的数组shell_code中的代码等效于int num2 = sum(1, 3);
unsigned char shell_code[] {
0x60, // pushad
0x6A, 3, // push 3
0x6A, 1, // push 1
0xFF, 0xD3, // call ebx(因为ebx存储的值是sum)
0x83, 0xC4, 8, // add esp, 8
0x89, 0x45, 0xE8, // mov num2, eax
0x61, // popad
0xFF, 0xE1, // jmp ecx(因为ecx存储的值是end_tag, 等效与jmp end_tag)
};
// 修改数组shell_code这段内存为可读可写可执行
DWORD oldProtect = 0;
VirtualProtect(shell_code, sizeof(shell_code), PAGE_EXECUTE_READWRITE, &oldProtect);
// 我们直接让CPU执行数组shell_code中的内容
__asm {
pushad // 保存寄存器当前存储的值
lea eax, shell_code // 把数组shell_code的地址放入eax
lea ecx, end_tag // 把end_tag地址放入ecx
jmp eax // 跳转到数组shell_code的首地址
}
end_tag:
__asm {
popad // 恢复寄存器原来的数值,恢复为pushad保存前的数值
pop ebx; // 恢复ebx寄存器原来的数值
}
std::cout << num2 << std::endl;
return 0;
}
上述代码执行结果如下: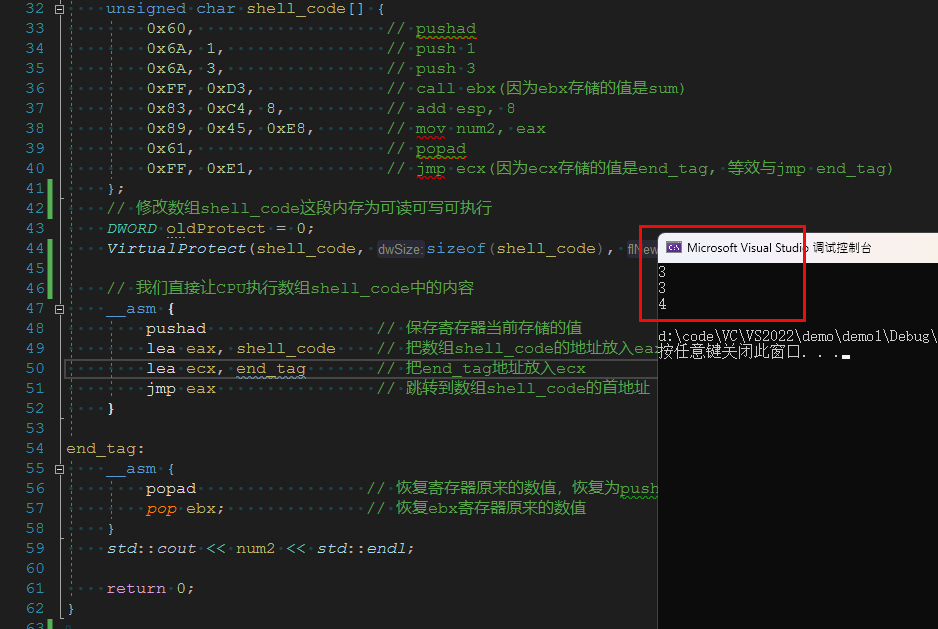
到此我们应该庆祝一下,现在我们已经掌握了让CPU直接执行0、1代码的方法。
但也别高兴的太早,似乎软件安全面临挑战,既然我们可以执行一段由0、1组成的shellcode buffer,那么不法分子也一样可以。如果我们代码有strycpy等类似函数,又没有对输入长度做检查,亦或memcpy(a,b,n)将b中的n个字符拷贝到a处。但是如果 n>a,那么都会存在缓冲区溢出攻击风险。只要不法分子精心构建一段由0、1组成的shellcode,那么我们软件、甚至整个操作系统都有可能受到威胁。
有兴趣进一步了解缓冲区溢出攻击的可以自行百度,或者参考文章 https://zhuanlan.zhihu.com/p/32473371 里的思路。
1. C++函数和C函数有区别吗?
1.1 C++类成员函数与C函数调用约定不同
首先我们大家一起回顾一下常见的函数调用约定。
|调用方式|参数入栈顺序|局部变量清理由谁清理|
|:-:|:-:|:-:|
|pascal|从左到右|函数内部清除(由编译器帮忙实现)|
|cdecl|从右到左|函数外部清除(由编译器帮忙实现)|
|fastcall|从右到左|函数内部清除(由编译器帮忙实现)|
|thiscall|从右到左|函数内部清除(由编译器帮忙实现)|
|__stdcall|从右到左|函数内部清除(由编译器帮忙实现)|
其他非常见:
nakedcall:一般出现在汇编中,编译器不会给这种函数增加初始化和清理代码。
vectorcall:尽可能利用寄存器来传递函数的参数变量,vectorcall对寄存器的使用数目多于fastcall。
__pascal: 是Pascal语言的函数调用方式,其特点是函数参数是从左到右的压栈方式入栈,局部变量在函数内部清除。(在windows下pascal已经不被msvc编译器所支持,PASCAL实际被编译器替换成了stdcall)__cdecl:是C和C++程序普通函数的缺省调用方式,其特点是函数参数是从右到左的压栈方式入栈,局部变量在函数外部清除。__fastcall:调用速度快,前两个(或若干个)参数由寄存器传递,其余参数还是通过堆栈传递。函数参数从右到左的压栈方式入栈,局部变量在函数内部清除。__thiscall:是C++类成员函数的调用方式,其特点是this指针被放在特定寄存器中(VC使用ecx),函数参数从右到左的压栈方式入栈,最后一个入栈的是this指,局部变量在函数内部清除.__stdcall:其特点函数参数从右到左的压栈方式入栈,局部变量在函数内部清除。
1 | // demo10.cpp |
对应的反汇编代码: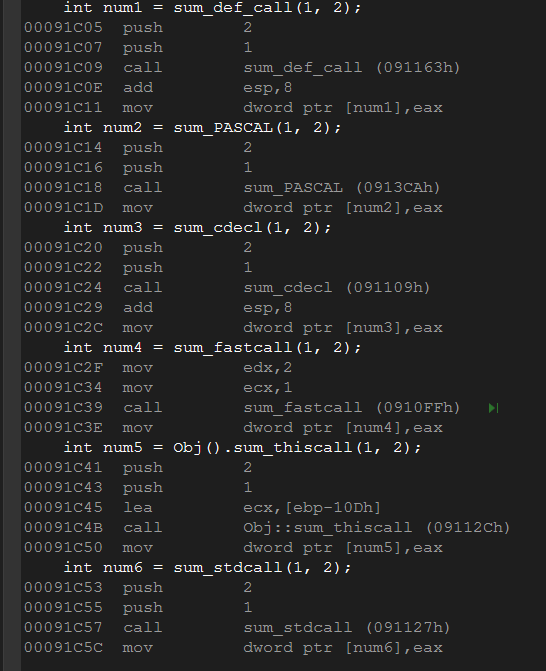
如果如果入栈参数所占用栈内存,不清理会怎么样?
会破坏栈平衡,可能会导致程序直接崩溃。
1.2 C++支持函数重载
1 | // demo3.cpp |
通过IDA,打开编译好的二进制文件,我可以看到: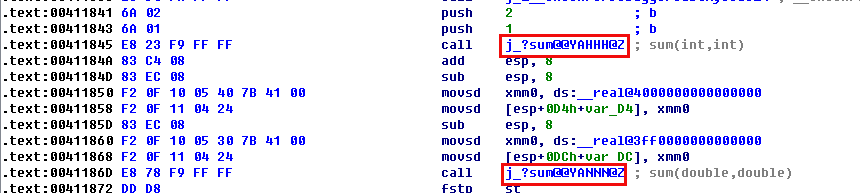
sum函数名,被编译器改为了j?sum@@YAHHH@Z和j?sum@@YANNN@Z,C++从而支持了函数重载。
1.3 C++支持默认参数
1 | // demo4.c |
代码demo4.c后缀为.C,启动编译编译,构建结果: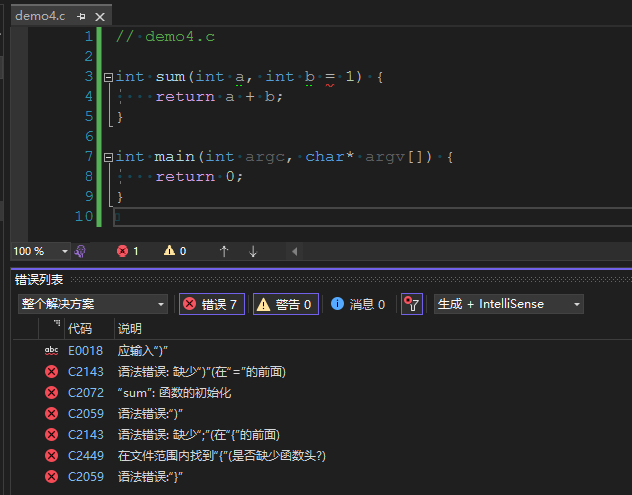
构建失败,说明C语言不支持默认参数。
1.4 C++支持仿函数
1 | // demo5.cpp |
1.5 C++支持std::function
1 | // demo6.cpp |

可以看到std::function通过std::function类中operator()操作符重载实现。(当然也可以直接std::function源码来学习具体实现)
1.6 C++支持std::bind
1 | // demo6.cpp |
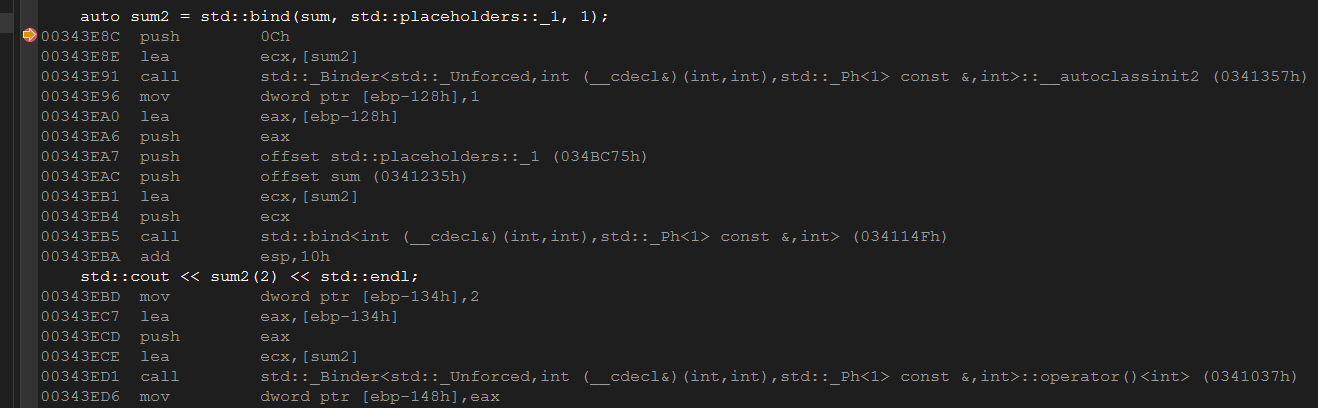
可以看到std::bind通过std::bind类中operator()操作符重载实现。(当然也可以直接查看std::bind源码来学习具体实现)
1.7 C++支持lambda表达式
1 | // demo6.cpp |

可以看到lambda表达式是通过匿名类,并且operator()操作符重载实现的。
2. C函数的调用过程是什么样的?
首先保护当前寄存器的数值,接着是参数入栈,然后调再用该函数,调用结束后接着做栈平衡,最后再恢复寄存的值为函数调用前的值。
3. C++函数的调用过程是什么样的?
1 | // demo7.cpp |
查看反汇编: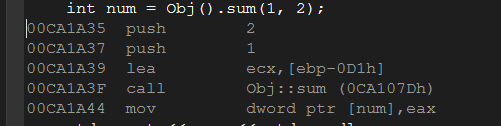
由此可以知:
C++普通函数调用过程和C函数是一样,C++类成员函数,调用过程和C函数类似,只是编译器把this指针存入了ecx(msvc编译器是这样,不同编译器可能用不同的寄存器。)
4. 类似 int sum(int, int)这样的函数,可以被正常调用并返回期望的结果吗?
1 | // demo8.cpp |
运行上边代码: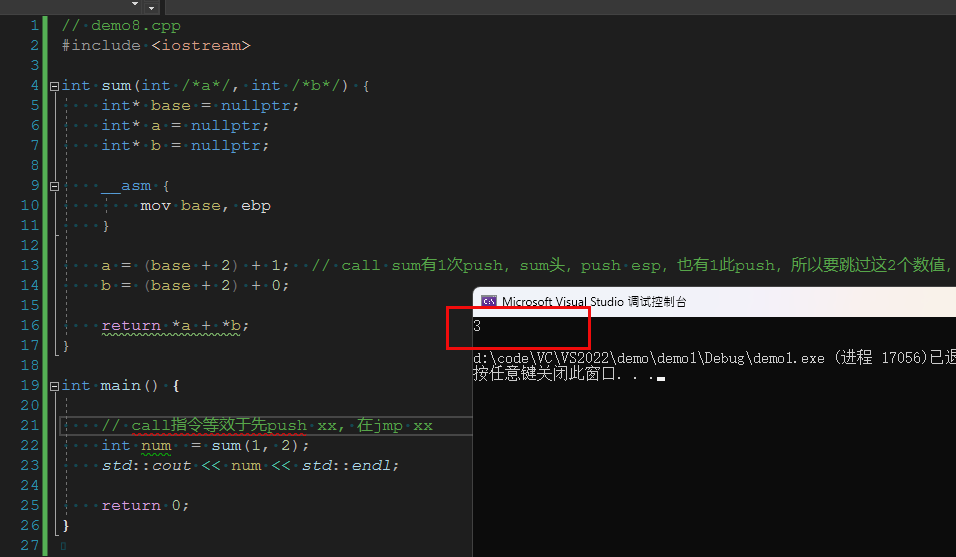
由此可知,我们可以通过寄存器esp指向的堆栈,直接拿到想要的参数变量的值,类似 int add(int, int)这种函数也就可以正常工作了。(因为函数来说,无论参数变量有无名称,最终都会被放到栈上,那么我们就有办法直接从栈上取到参数对应的变量)
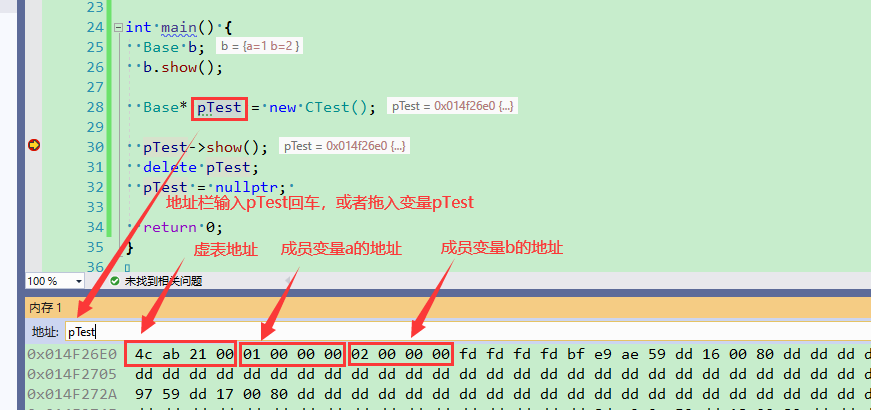
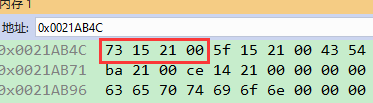
Obj* obj = nullptr; obj->show(); obj->get_name();可以编译通过吗?如果可以,运行后会显示什么?
1 |
|
执行上述代码: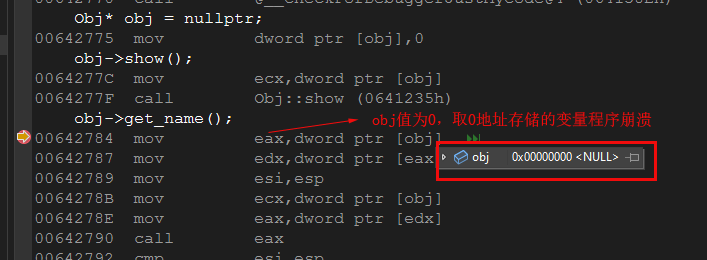
obj->show();是可以调用的,show()属于类,不管有没有类实例,show()都是存在的(被所有类实例共享)。
obj->get_name();由于需要先找到虚表,再从虚表找到get_name()函数的地址,虚表放在obj的首地址,而obj值是nullptr,程序崩溃
最后,只要我们要学会了善于利用调试器,以及调试器里边的反汇编功能,假以时日,那些看似遥不可及的C++底层原理,也必然为我们所用!
一些题外话:
当下还有什么工程用到了汇编么吗?
1.Linux内核:https://github.com/torvalds/linux/blob/master/arch/x86/boot/copy.S
2.FFmpeg多媒体框架:https://github.com/FFmpeg/FFmpeg/tree/master/libavutil/x86
3.OpenSSL加密库:https://github.com/openssl/openssl/tree/master/crypto/x86
4.GCC编译器:https://github.com/gcc-mirror/gcc/blob/master/gcc/config/i386/i386.cc
5.NASM汇编器:https://github.com/netwide-assembler/nasm
6.libyuv:https://github.com/sayrer/libyuv/blob/master/source/scale_win.cc libyuv是google 开源的用于实现对各种yuv数据之间的转换包括裁剪、缩放、旋转,以及yuv和rgb 之间的转换,底层有一部分代码是基于汇编实现的,大大提高了转换速度。
libyuv被广泛用于 音视频SDK中。
编程就像修高楼,只有夯实基础,万丈高楼才能平地起,这样的大楼自然经得住风吹雨打!